VRChatで使用しているアバターのパフォーマンスランクが「Very Poor」になってしまうことがあります。Very Poorランクは、ワールドによっては表示が制限されたり、他ユーザーへの負荷となる可能性も指摘されており、可能な範囲での最適化が推奨されています。
今回は、Unityのツール「Mantis LOD Editor」と「MeshDeleterWithTexture」を用いて、アバターのポリゴン数を削減し、パフォーマンスランクを「Very Poor」から「Poor」へ改善することができたため、その手順と方法を記録としてまとめます。
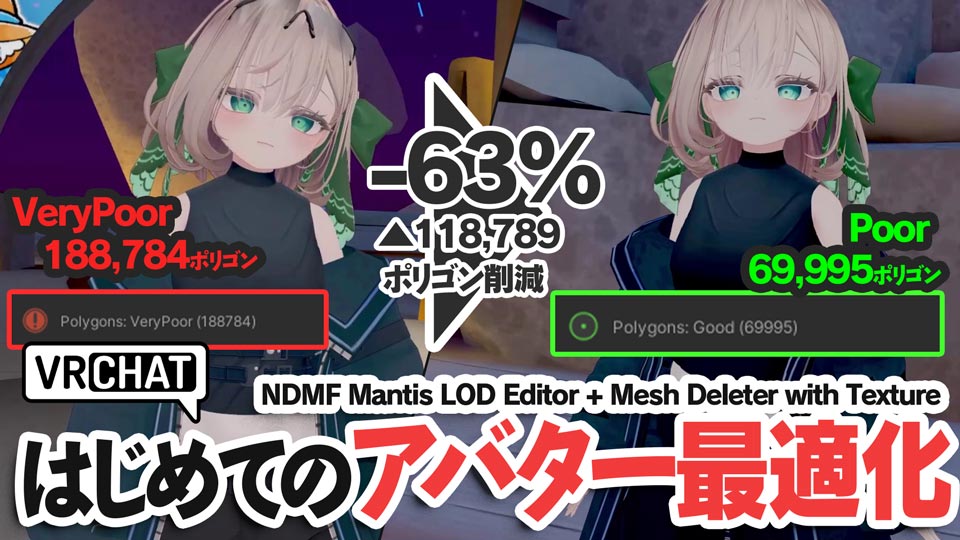
【最適化結果:ビフォーアフター】
最適化前: 188,784ポリゴン / パフォーマンスランク: Very Poor

最適化後: 69,995ポリゴン / パフォーマンスランク: Poor

上記のように、見た目への影響を最小限に抑えつつ、ポリゴン数を63%削減することに成功しました!
具体的には、以下の方法でポリゴン数を効果的に削減しました。これらのテクニックは、アバター改変や自作モデル制作においても重要になると思われます。
- 隠れたパーツの削除: 服の下で見えない体の一部(肘など)のメッシュを削除。
- Mantis LOD Editorによる削減: 各パーツ(服、髪、小物など)のポリゴン数を、見た目が崩れない範囲で削減。
- MeshDeleterWithTextureによる部分削除: 服の不要な装飾や、さらに隠れた部分のメッシュをテクスチャ指定で削除。
- (応用)MeshDeleterによるパーツ分離: 複合パーツ(例:インナーとアウターが一体化した服)を分離し、それぞれ個別に最適化。
この記事では、これらの手順を順番に解説していきます。
この記事の内容
最適化に必要なツールと準備
今回のVRChatアバター最適化(ポリゴン削減)で使用した主なツールは以下の通りです。
- Mantis LOD Editor – Professional Edition (Unity Asset Store / 有料: 約$55)
- 高品質なポリゴン削減(リダクション)機能を持つ定番のUnityアセット。アバターの各パーツのポリゴン数を効率的に減らせます。購入後、UnityのPackageManager > My Assetsからインポートします。
- 【非破壊でポリゴン削減】Mantis LOD EditorのNDMF化ツール (Booth: ひつぶさん作 / 無料 ※Mantis LOD Editor本体が必要)
- 上記のMantis LOD Editorを、VRChatアバター改変で広く使われているフレームワーク「NDMF(なでもふ)」上で、より安全かつ簡単に(非破壊的に)利用できるようにするツール。Boothからダウンロードし、unitypackageをインポートします。実際にアバターに適用するのはこちらです。
- MeshDeleterWithTexture beta (Booth: がとーしょこらさん作 / 無料)
- テクスチャ画像上で範囲を指定することで、対応するメッシュ部分を削除(実際には新しいメッシュを生成)できる非常に便利なUnityエディタ拡張。Mantisでは難しい、服の細かい装飾の削除や、隠れた部分のメッシュ除去に役立ちます。Boothからダウンロードし、unitypackageをインポートします。
- anatawa12’s VRC Avatar Tools (旧: gists pack) (VCC経由で導入可能)
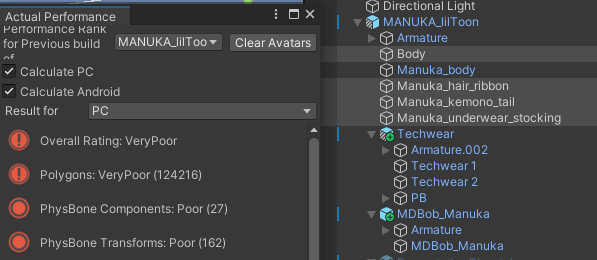
- アバターのパフォーマンス統計情報を詳細に表示する機能などが含まれるツール群。特に「Actual Performance」タブは、最適化作業中の現在のポリゴン数やパフォーマンスランクをリアルタイムで確認するために必須です。VCC (VRChat Creator Companion) の「Manage Project」から簡単に追加できます。
【重要】Actual Performanceタブでの確認方法:
anatawa12’s VRC Avatar Toolsを導入すると、VRChat SDK Control Panelに「Avatars」タブが追加され、その中に「Actual Performance」という項目が表示されます。MantisやMeshDeleterで最適化を行った後、Unityを再生モード(Play Mode)にすると、このタブの情報が更新され、最新のポリゴン数やパフォーマンスランクを確認できます。目標は、ここの「Polygons」の数値を70,000以下にすることです(Poorランクの上限)。
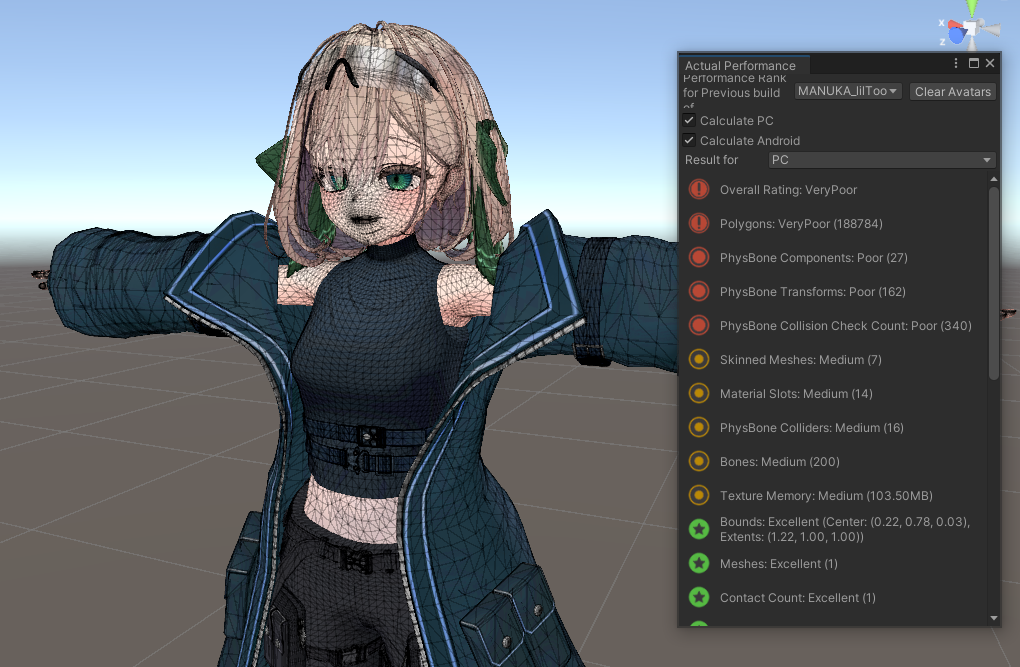
(↑この例では188,784ポリゴンでVery Poor。目標は70,000ポリゴン以下!)
知っておくと便利な専門用語(非破壊的, NDMF)
アバター最適化を進める上で、いくつか知っておくと理解が深まる用語があります。
- 非破壊的 (Non-Destructive)
元のデータを直接書き換えずに行う編集方法のこと。今回使うNDMF版MantisやMeshDeleterは、元のメッシュデータを保持したまま処理を行うため、「非破壊的」です。つまり、設定を間違えたり、結果が気に入らなかったりした場合でも、ツール(コンポーネント)を削除したり設定を戻したりするだけで、簡単に元の状態に戻すことができます。初心者でも安心して試せる大きなメリットです。 - NDMF (Nade Nadenadeshiko Mod Fwk / なでもふ)
VRChatアバター改変のためのフレームワーク(仕組み)の一つ。アバターの色々な設定や改変を「コンポーネント」として管理し、それらをビルド時に自動で適用してくれます。非破壊的な改変と相性が良く、多くの便利ツールがNDMFに対応しています。今回使う「Mantis LOD EditorのNDMF化ツール」もその一つです。
Mantis LOD Editorを使ったポリゴン削減の基本
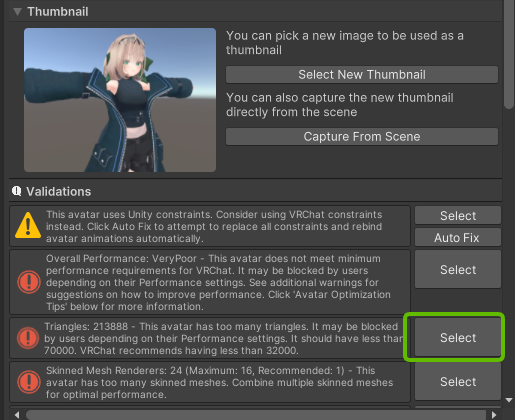
まずは、アバターの中でどのパーツがポリゴン数を増やしている主犯なのかを特定しましょう。
1. UnityでVRChat SDK Control Panelを開き、「Builder」タブを選択します。
2. アバターを選択した状態でビルドを実行しようとすると、パフォーマンスに関する警告(Validation Results)が表示されます。「Polygons」に関する警告メッセージの横にある「Select」ボタンをクリックすると、ポリゴン数が特に多いメッシュ(衣装パーツなど)がHierarchyウィンドウでハイライトされます。
3. ハイライトされたオブジェクト(衣装パーツなど)に、「NDMF Mantis LOD Editor」コンポーネントを追加します。(Inspectorウィンドウで「Add Component」し、”Mantis”で検索すると見つかります)
4. 追加されたコンポーネントの「Quality」スライダーを調整します。この数値を下げるほどポリゴン数が削減されますが、下げすぎるとメッシュの形が崩れてしまいます。
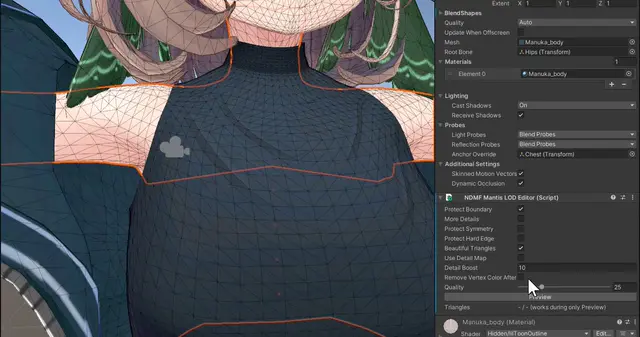
【ポイント】Shaded Wireframe表示を活用しよう
Qualityスライダーを調整する際は、Unityのシーンビュー表示を「Shaded Wireframe」に切り替えると、ポリゴンの削減具合やメッシュの崩れ具合が視覚的に分かりやすくなります。「Shaded」表示と適宜切り替えながら、見た目を損なわないギリギリのラインを探っていきましょう。
この「パーツ特定 → コンポーネント追加 → Quality調整」を、ポリゴン数が多いパーツに対して繰り返していくのが基本的な流れです。
【重要】使わないパーツは完全に削除しよう
アバター改変をしていると、「元の服や髪型も、いつか使うかもしれないから一応残しておこう」と、非表示にしただけでHierarchyに残してしまうことがあります。しかし、非表示にしただけのメッシュもポリゴン数としてカウントされてしまう場合があります!
今回の私のアバターも、元のマヌカちゃんのエプロンパーツなどを非表示で残していましたが、これらをHierarchyから完全に削除したところ、約16,000ポリゴンも削減できました。
使わないパーツは思い切って削除しましょう。もし後で必要になった場合は、元のアバターや衣装のunitypackageを再インポートすれば簡単に戻せます。
(参考: UnityだけでVRChatアバターのVeryPoorを脱出する方法|こはだ 様)
【注意】顔と素体のポリゴン削減は慎重に!

Mantisでのポリゴン削減は効果的ですが、アバターの「顔」と「素体(Body)」のメッシュは、原則として削減しない方が無難です。
特に顔周りは、豊かな表情を作るために非常に多くの細かいポリゴン(メッシュ)で構成されています。口周りのポリゴンはリップシンク(口パク)の様々な形に対応するため、目周りのポリゴンはまばたきや感情表現のために必要です。
これらの部分をMantisで安易に削減してしまうと、喋るたびに口が破綻したり、表情が崩壊したりする可能性が非常に高くなります。同様に、素体の関節部分なども、削減するとポーズを取ったときに不自然な見た目になりやすいです。
ポリゴン削減は、主に服、髪、アクセサリーなどのパーツで行い、顔と素体はできるだけ元の状態を保つようにしましょう。
【判断】時にはデザイン的な妥協も必要

どうしても目標のポリゴン数(Poorランクの70,000ポリゴン)に収まらない場合、デザインの一部を諦めるという判断が必要になることもあります。
今回のアバターでは、尻尾パーツのポリゴン数をMantisである程度削減しましたが、それでも目標達成が難しかったため、最終的に尻尾パーツ自体を削除する決断をしました。もちろん残念ですが、パフォーマンスランク改善のためには、こうしたトレードオフが必要になる場合もあります。
Mantisだけでは難しいケースと課題
Mantis LOD Editorは非常に優秀なツールですが、最適化を進める中で、Mantisだけでは対応が難しい、あるいは効率が悪いと感じる場面が出てきました。
- 複合パーツの削減限界: インナーとアウターが一体化している服など、一つのオブジェクトに複数の部位が含まれている場合、Mantisで削減すると、先にポリゴン数が少ない部分(例: インナー)が破綻してしまい、ポリゴン数が多い部分(例: アウター)を十分に削減できないことがある。パーツを分離して個別に削減したい。
- 隠れたメッシュの残り: 服の下に隠れている素体の一部(例: お腹周り)を非表示にしてもメッシュが残り、ポリゴン数に含まれてしまう。この隠れた部分だけを削除したい。
- 部分的な装飾の削除: 服の特定の部分(ポケット、ベルト、フリルなど)だけを削除してポリゴン数を稼ぎたいが、Mantisでは全体的な削減しかできない。
これらの課題を解決するために役立つのが、「MeshDeleterWithTexture beta」です。
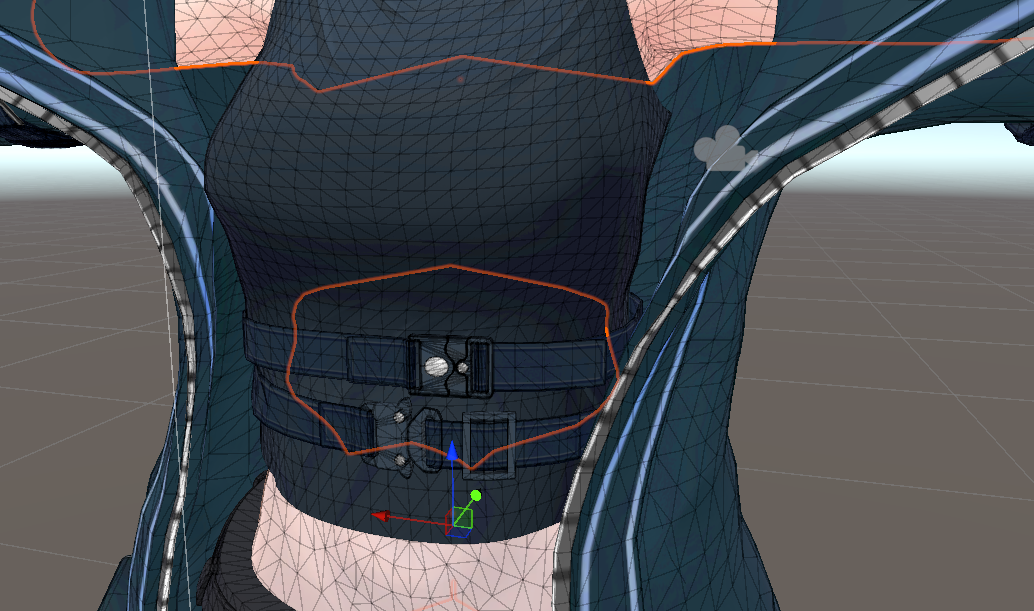
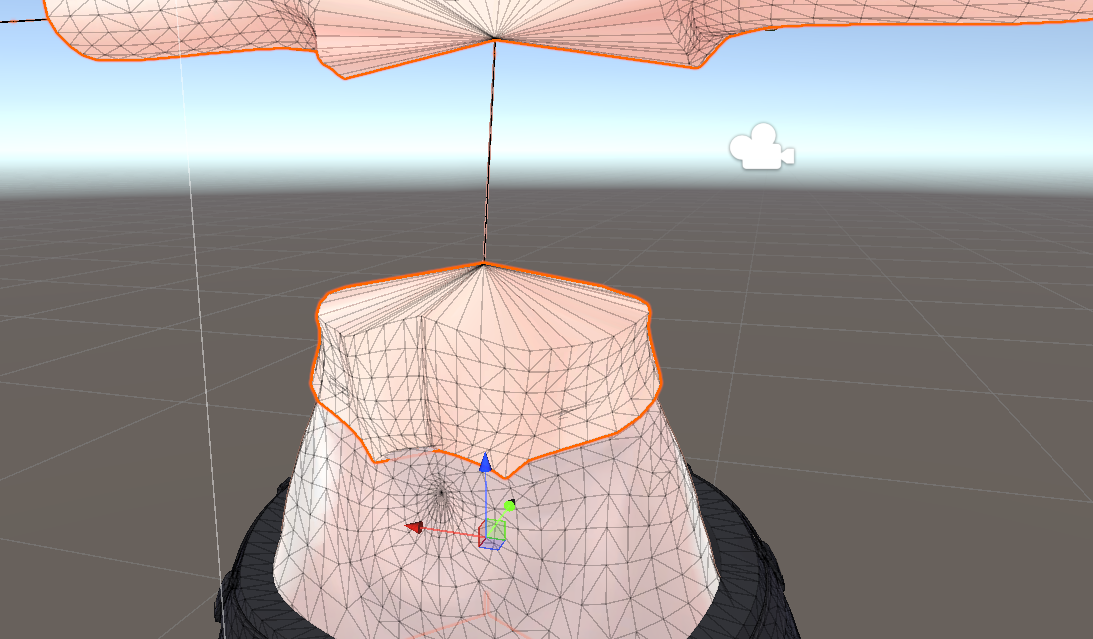
(↑例えば、服の下に隠れているこのお腹部分のメッシュを削除したい)
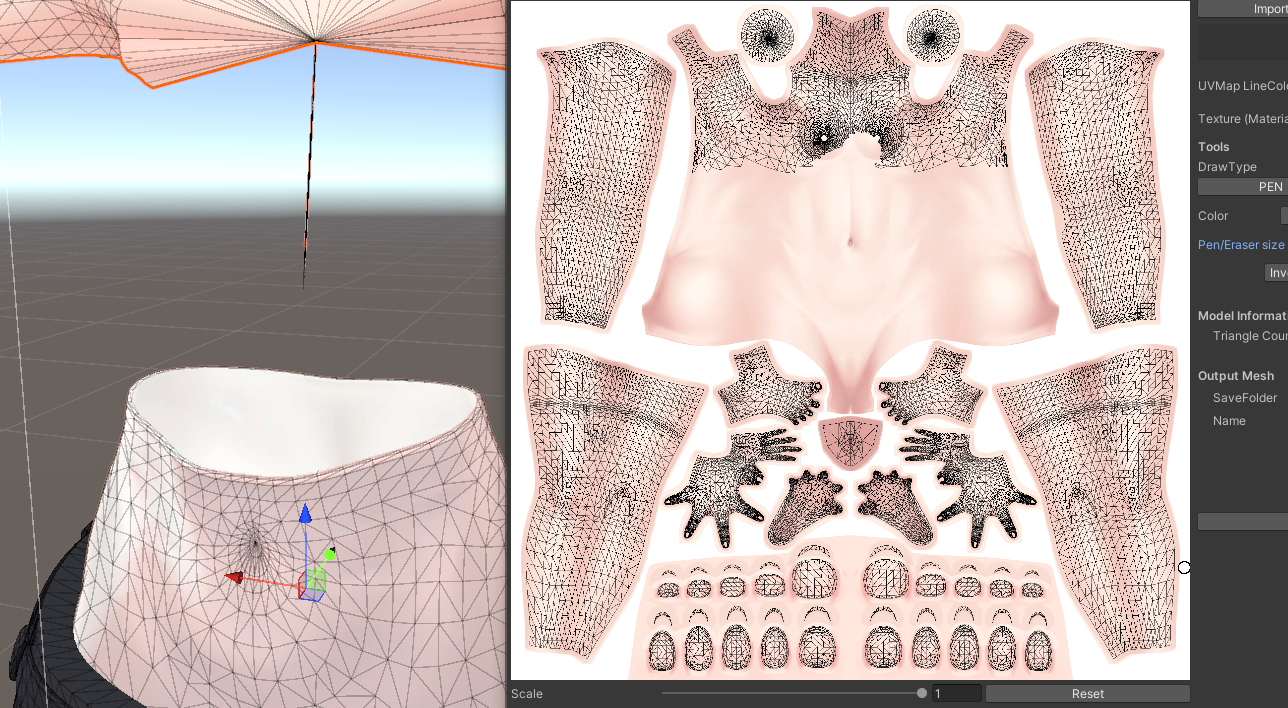
MeshDeleterWithTexture betaを使った部分的なメッシュ削除
「MeshDeleterWithTexture beta」は、その名の通り、テクスチャ画像上で指定した範囲に対応するメッシュ部分を削除(正確には、削除した新しいメッシュを生成)してくれる画期的なツールです。
使い方は非常に直感的です。
1. がとーしょこらさんのBoothからunitypackageをダウンロードし、プロジェクトにインポートします。
2. Unityメニューバーに「GotoTools」という項目が追加されるので、「MeshDeleter with Texture」を選択して専用ウィンドウを開きます。
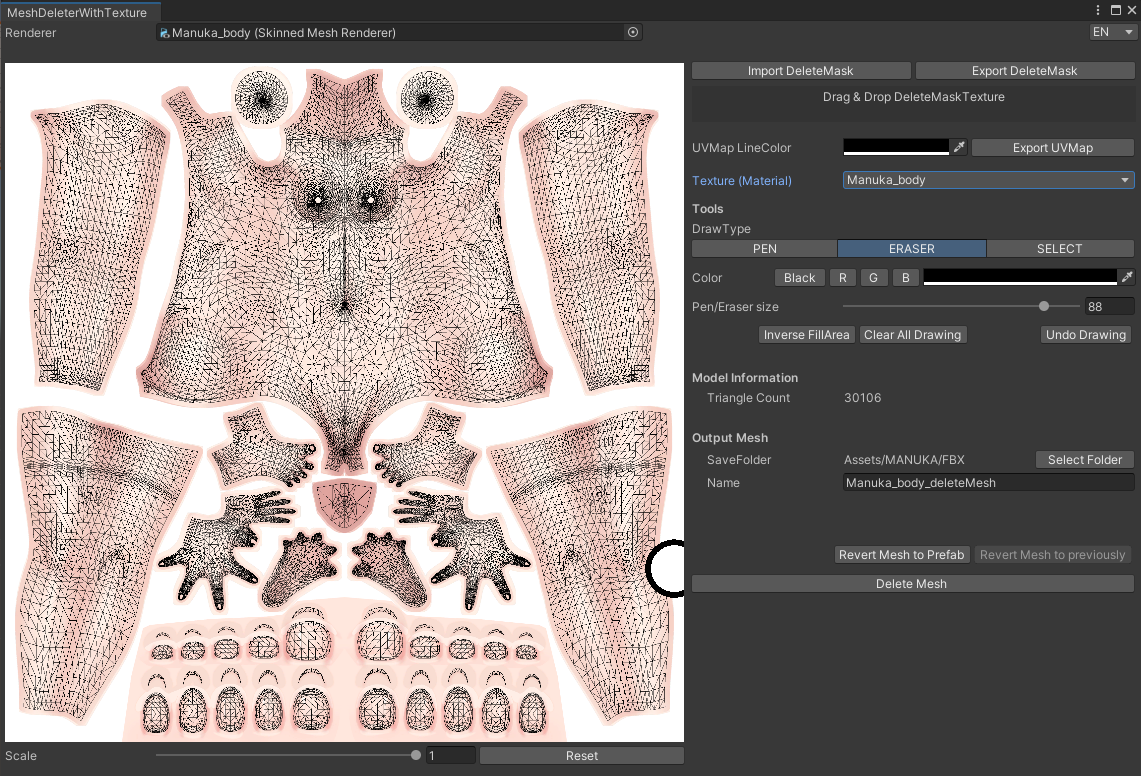
3. ウィンドウ上部の「Renderer」という欄に、メッシュを削除したいオブジェクト(例: 体のメッシュを持つオブジェクト)をHierarchyウィンドウからドラッグ&ドロップします。
4. オブジェクトに設定されているテクスチャ画像がウィンドウ内に表示されます。
5. 画面右側の「Draw Type」から「PEN」などを選択し、テクスチャ上で削除したい部分(例: 服で隠れるお腹の部分)を黒く塗りつぶします。塗りつぶした部分は、シーンビュー上のモデルにもリアルタイムで反映され、削除される範囲を確認できます。
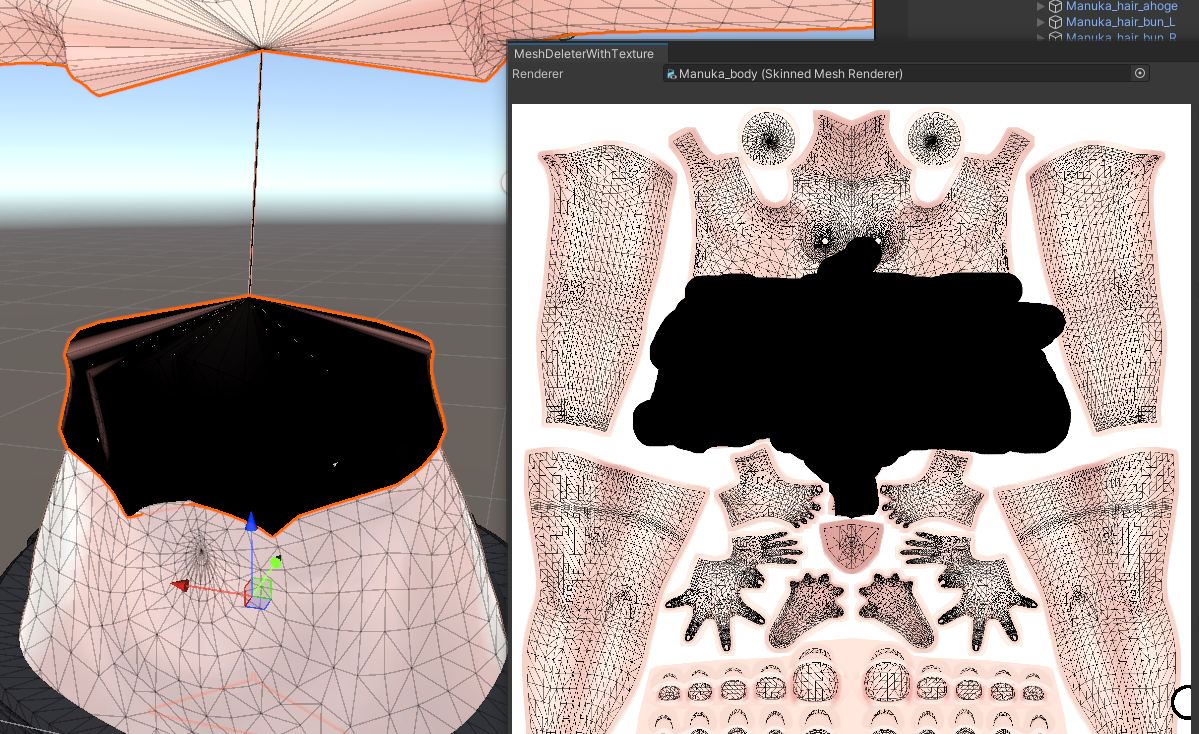
6. 削除範囲を確認したら、「DeleteMesh」ボタンをクリックします。これで、指定した部分が削除された新しいメッシュが生成され、オブジェクトに自動で適用されます。
【ポイント】MeshDeleterも非破壊的!
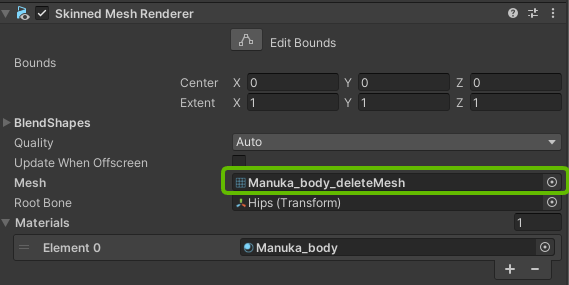
このツールも「非破壊的」で、元のメッシュデータはプロジェクト内に残っています。もし削除範囲を間違えたり、元に戻したくなったりした場合は、オブジェクトのMesh Renderer(またはSkinned Mesh Renderer)コンポーネントで、Meshの指定を元のファイルに戻すだけでOKです。安心して試せますね。
この方法で、服の下に隠れていた腹部メッシュを削除したところ、約1,000ポリゴン削減できました。さらに、残った部分にMantis LOD Editorを適用して、より効率的にポリゴンを削減することも可能です。
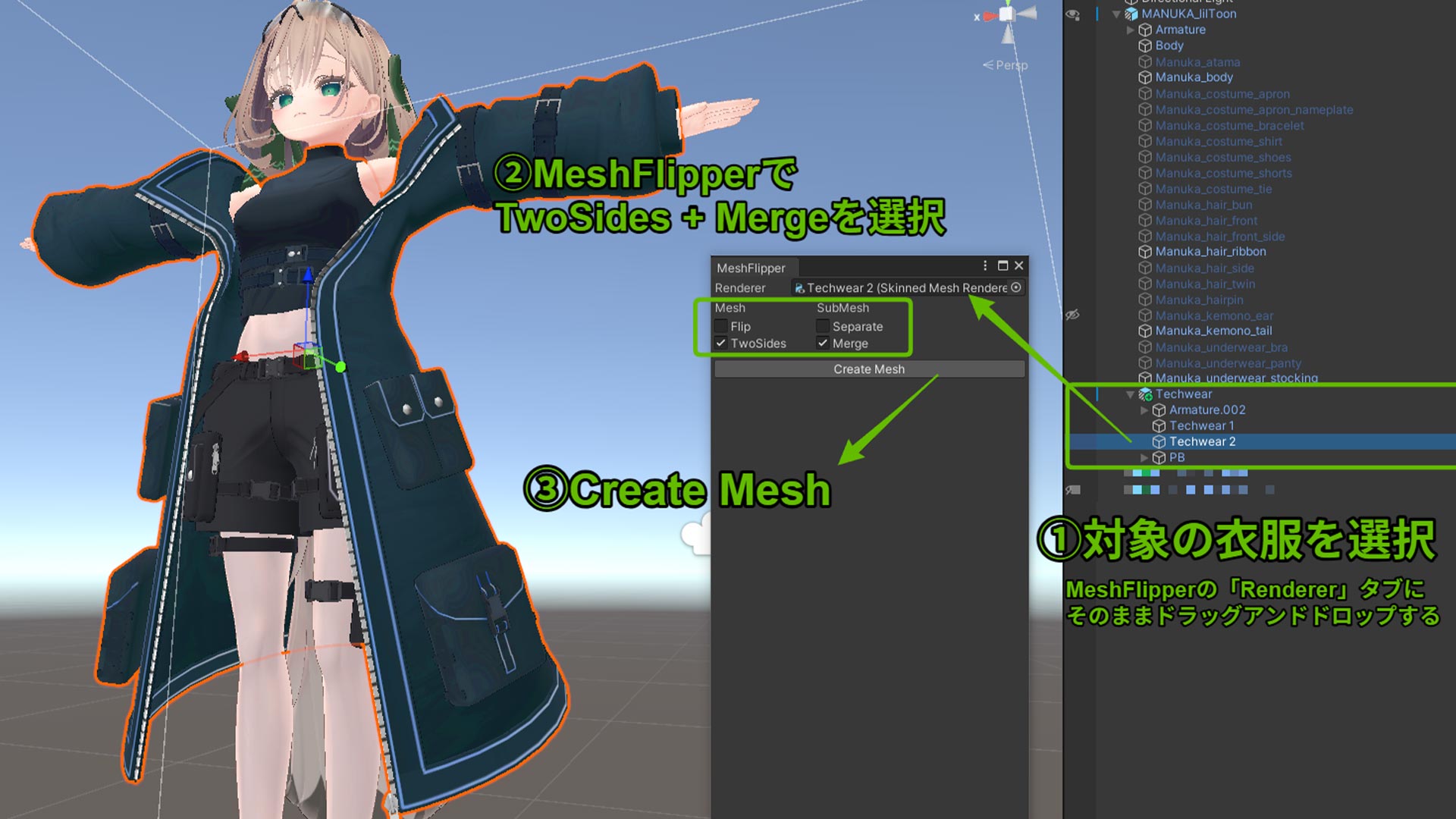
応用テクニック:MeshDeleterで服パーツを分離する
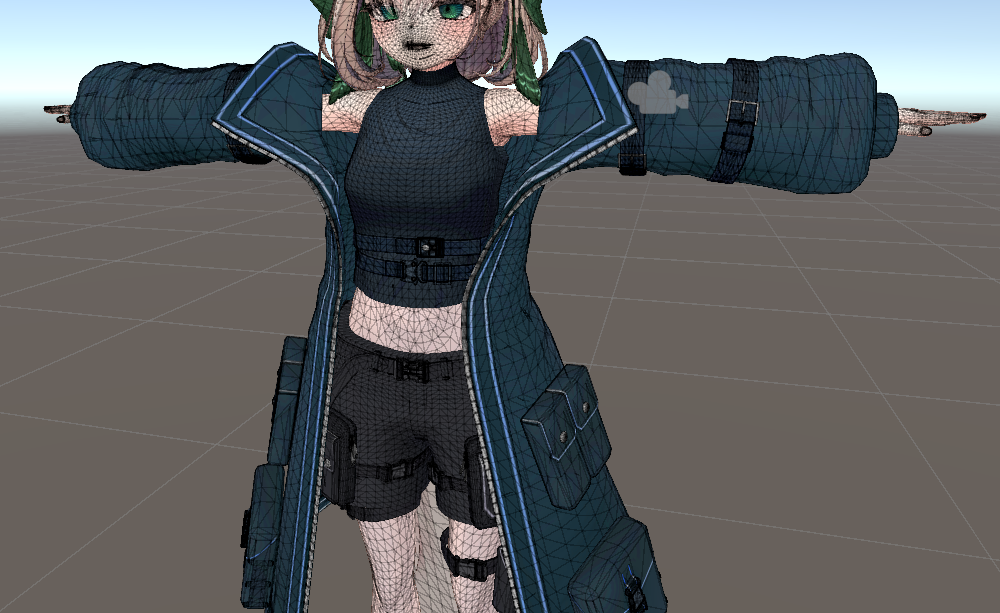
MeshDeleterの「テクスチャ範囲指定でメッシュを削除する」機能は、応用することで一体化している服パーツを分離するのにも使えます。
今回使用したテックウェア(約60,000ポリゴン)は、コート部分(アウター)と上半身のインナーが同じ一つのオブジェクト(メッシュ)として作られていました。このままだと、Mantisで削減しようとしても、ポリゴン数の少ないインナー部分が先に破綻してしまい、ポリゴン数の多いコート部分を十分に削減できませんでした。
そこで、MeshDeleterを使って「インナーだけのメッシュ」と「アウターだけのメッシュ」を擬似的に作り出すことにしました。
【パーツ分離手順】
1. 元のテックウェアオブジェクトをHierarchy上で複製(Ctrl+D または Cmd+D)し、それぞれ「インナー用」「アウター用」など分かりやすい名前に変更します。
2. 「インナー用」オブジェクトを選択し、MeshDeleterウィンドウを開きます。
3. テクスチャ上で、アウター(コート)に対応する部分をすべて黒く塗りつぶし、「DeleteMesh」を実行します。これにより、インナー部分だけが残ったメッシュが生成されます。
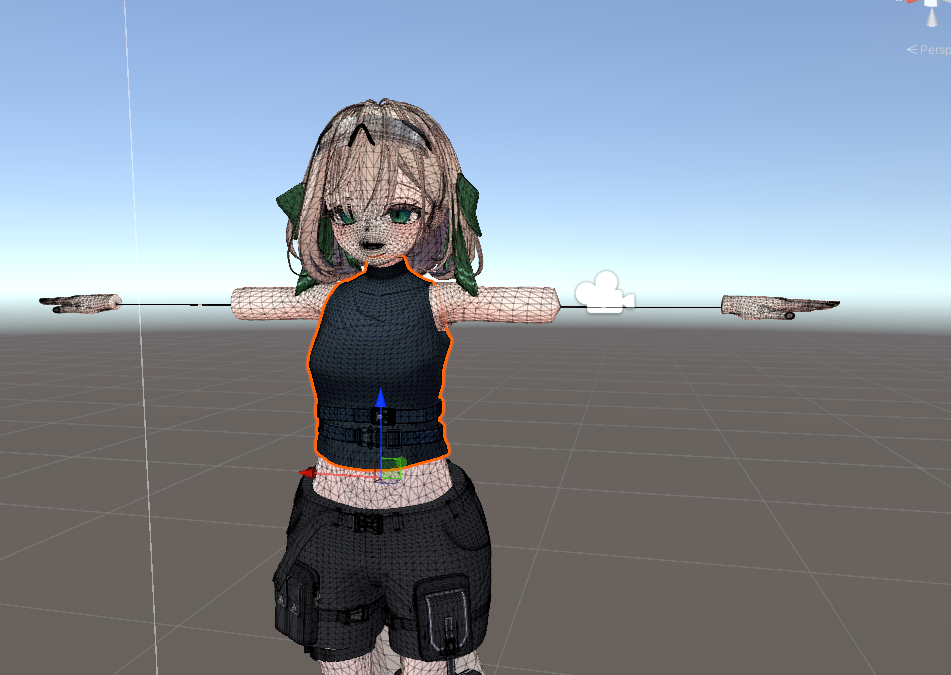
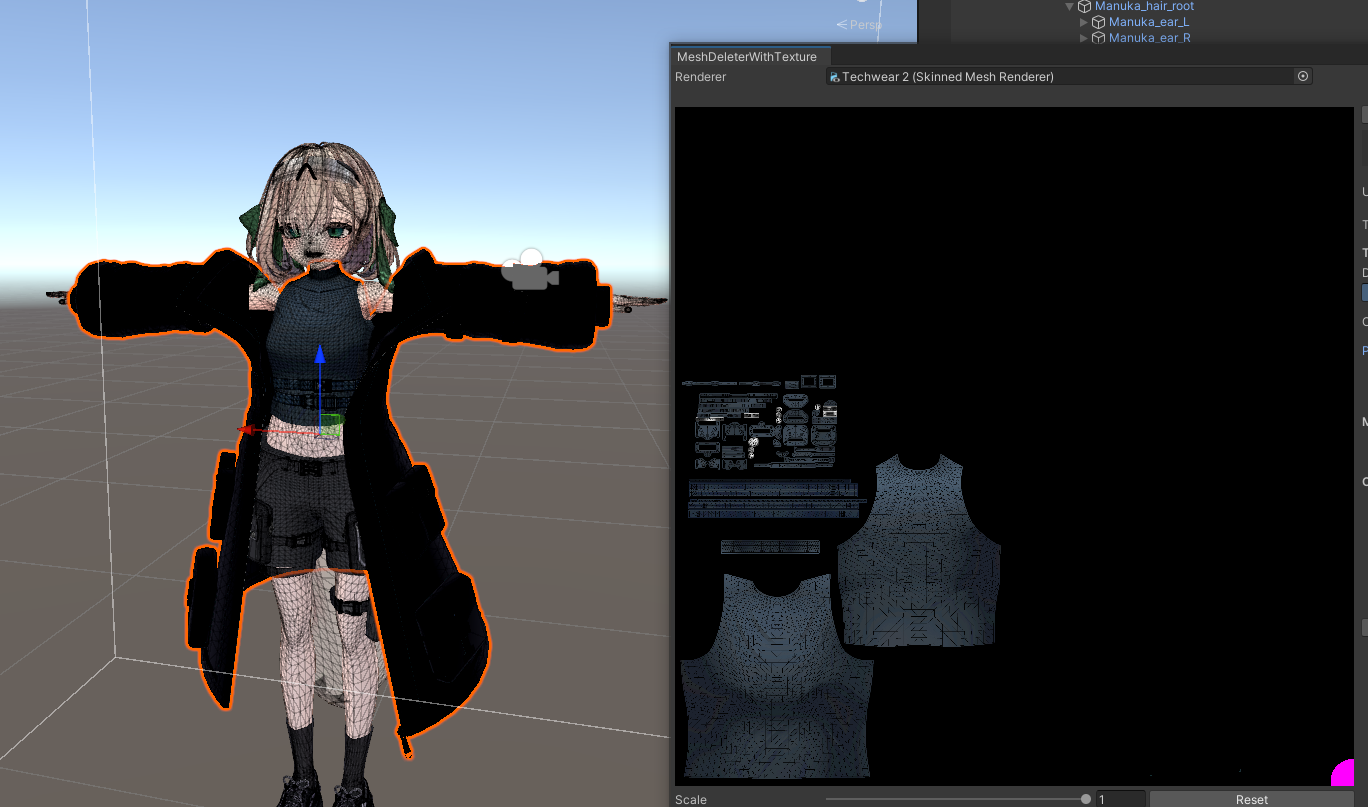
4. 同様に、「アウター用」オブジェクトを選択し、MeshDeleterウィンドウで今度はインナーに対応する部分をすべて黒く塗りつぶし、「DeleteMesh」を実行します。これにより、アウター(コート)部分だけが残ったメッシュが生成されます。
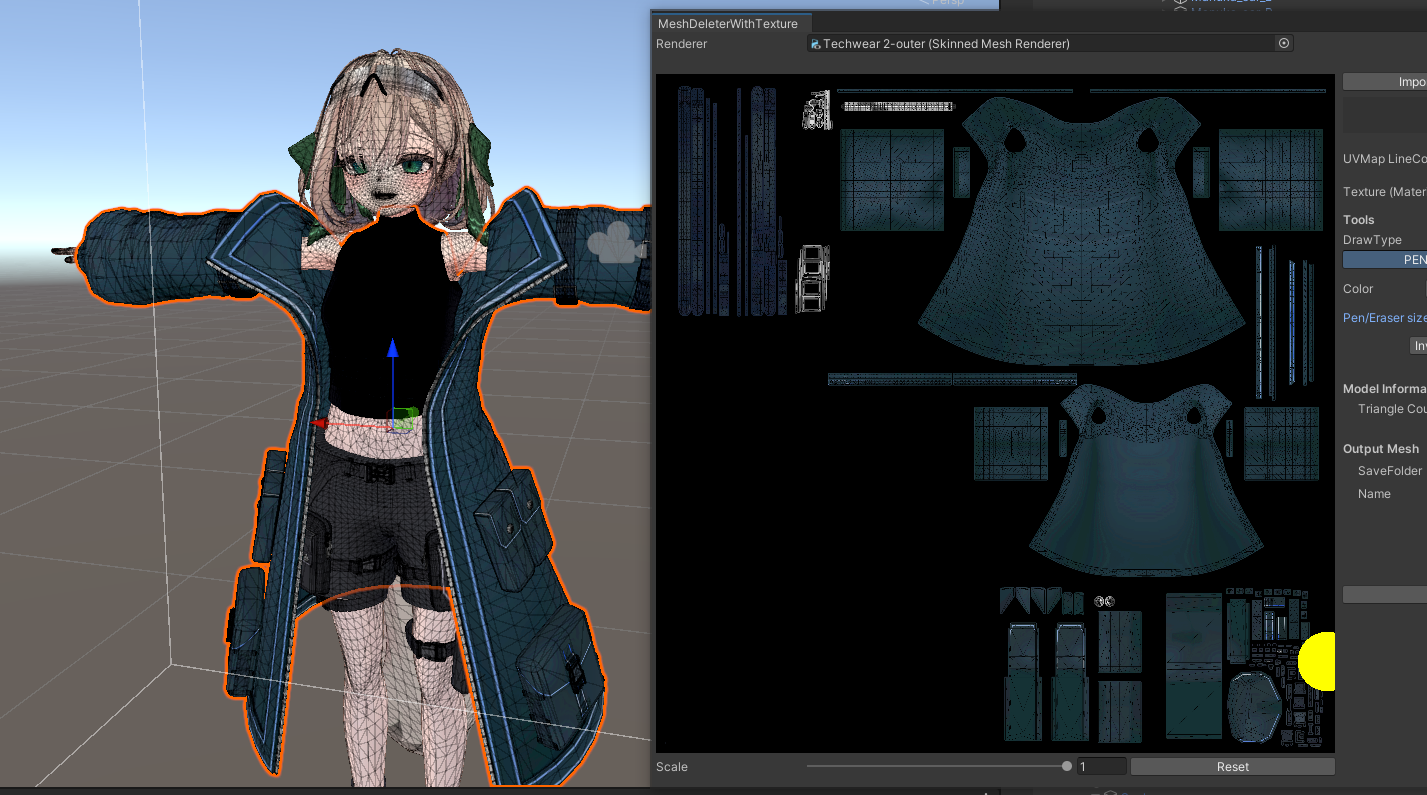
これで、もともと一体だった服を「インナー」と「アウター」の2つのメッシュに分離できました。Blenderなどの外部モデリングソフトを使わずに、Unity上だけでパーツを分離できるのは非常に便利です。
分離後は、それぞれのパーツ(インナー、アウター)に個別にNDMF Mantis LOD Editorを適用し、より効果的にポリゴン数を削減していくことが可能になります。
まとめ:Very Poor脱出!最適化の成果とポイント
以上の方法を用いた結果、最初に18万ポリゴンあったVeryPoorランクのアバターを、69,995ポリゴンのPoorランクに改善することができました。
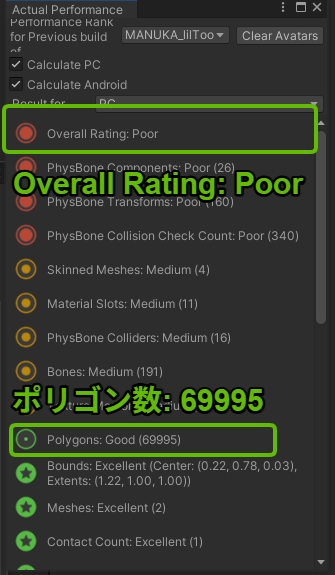
最終的に目標の70,000ポリゴン以下に収めるために、服の装飾削除やコートのポリゴン削減など、デザイン面での調整も行いました。見た目を維持しながらポリゴン数を削減する作業は、試行錯誤が必要ですが、非常に良い練習になったと感じています。

今回使用した「Mantis LOD Editor (NDMF版)」と「MeshDeleterWithTexture beta」は、どちらも非破壊的なツールであるため、初心者でも比較的安心して試すことができます。「いつでも元に戻せる」という点は、最適化作業を進める上での大きな心理的な支えになります。
Mantisの強力なポリゴン削減能力と、MeshDeleterの柔軟な部分編集・応用力を組み合わせることで、Very Poorランクのアバターも効果的に最適化できる可能性が高まります。
VRChatアバターのポリゴン数でお悩みの方は、ぜひこの記事で紹介したツールと手順を参考に、最適化に挑戦してみてください。(なお、パフォーマンスランクにはポリゴン数以外にもマテリアル数などが影響するため、総合的な最適化を目指す場合はそちらも考慮が必要です)
参考にさせていただいた情報
今回のアバター最適化(ポリゴン削減)にあたり、以下の記事や動画を大変参考にさせていただきました。素晴らしい情報をありがとうございます。
- 【第5回】lil NDMF Mesh Simplifier VS Mantis LOD Editor ポリゴン削減比較&解説【VeryPoor→Medium】 – INSTチャンネル YouTube (※元のリンクがYouTube検索結果になっていたためダミーリンクにしています。実際の動画を検索してください)
- 非破壊でポリゴン削減! Mantis LOD EditorのNDMF化ツールを紹介! | メタカル最前線
- 【2024年11月最新版】VCCにこれは入れておけ! アバター改変の便利ツール紹介 | メタカル最前線
- Mantis LOD Editorを使ってアバターを2万ポリ以下にする【VRChat】|すゞは
- UnityだけでVRChatアバターのVeryPoorを脱出する方法|こはだ
追記:ハイエンドモデル最適化の限界と注意点 (2025年4月)
この記事ではVery PoorランクのアバターをPoorランクに改善する手順を紹介しましたが、すべてのケースで同様の最適化が最善とは限らない点について追記します。特に、元のポリゴン数が非常に多い、いわゆる「ハイエンドモデル」の最適化には注意が必要です。
これらのモデルは、ディテールに富んだ装飾や複雑な衣装、多くのギミックなどが魅力ですが、その分ポリゴン数が膨大(10万ポリゴンをはるかに超えることも珍しくありません)です。このようなモデルに対してMantis LOD Editorなどでポリゴン削減を行うと、わずかな削減率でも見た目のディテールが失われ、モデル本来の魅力が大きく損なわれてしまう可能性があります。
Poorランクの規定(7万ポリゴン)を少しオーバーしている程度のアバター(例えば7万~10万ポリゴン程度)や、もともとシンプルなデザインのデフォルメモデルなどであれば、この記事で紹介した方法は有効でしょう。しかし、規定の倍以上、例えば15万、20万ポリゴンを超えるようなハイエンドモデルを、見た目を維持したままPoorランクまで無理に削減しようとすることは、多くの場合困難であり、あまり推奨できません。
では、どうすれば良いかというと、無理に一つのモデルを極端に最適化するのではなく、用途に応じた使い分けを検討するのが現実的です。
- 通常利用: メインのアバターは、最適化せず元のクオリティのまま使用する。
- 軽量化が必要な場面: 大人数が集まるイベントや、パフォーマンスが重視される特定のワールドに参加する際には、別途軽量化されたバージョン(Quest対応版などが用意されている場合もあります)を用意するか、あるいは最初から軽量な別のアバターを使用する。
【筆者の体験談と反省】
実を言うと、今回Poorランク(69,995ポリゴン)まで最適化したマヌカ改変モデルですが、しばらく使ってみて、少し考えが変わりました。確かに軽量化には成功したのですが、その過程で服の細かい装飾などを一部削除してしまったことに対し、「そこまでして最適化する必要があったかな?」という気持ちが後から出てきました。
また、私自身のVRChatのプレイスタイルとして、パフォーマンスが非常にシビアなワールドに頻繁に参加するわけではなかったため、「このモデルに関しては、Very Poorのままでも大きな支障はなかったかもしれない」というのが正直なところです。
アバターの最適化は、VRChatを快適に楽しむ上で重要な要素の一つですが、それが常に必須というわけではありません。ご自身のプレイスタイルや参加するコミュニティ、そして「どの程度の見た目の変化なら許容できるか」をよく考慮した上で、最適化を行うかどうか、どのレベルまで行うかを判断することが大切だと思います。